Hello and welcome, happy readers! I hope you are well and in good health in these difficult times.
Today I would like to talk to you about clinical decision support systems- early implementations, the existing types, and state of the art techniques.
Clinical decision support systems (CDSS) are computer-based programs that support clinicians in their decision-making process by providing information extracted from patient data. One of the earliest implementations of a CDSS is the MYCIN system developed by Edward Shortliffe in the early 1970s. If you are well versed in clinical lingo, the name may already reveal to you what the goal of MYCIN was: the recommendation of antibiotics to patients with bacterial infections (antibiotics often carry the suffix “-mycin”).
MYCIN was designed with several constraints in mind. To motivate clinicians to participate in the project, a task had to be chosen that would be of the clinicians’ interest. Previous research indicated that antibiotics were often administered inefficiently, making the topic a valuable target for decision support. Given the complexity and continuous evolution of the medical field, the system needed to manage a large, constantly changing body of information, as well as possess the ability to communicate with the user effectively. Results that were computed by the system needed to be explained to the user- the systems aim was to support physicians rather than replace them. After all, engineers will gladly assist clinicians, but we will not take responsibility for patient outcomes. 😉
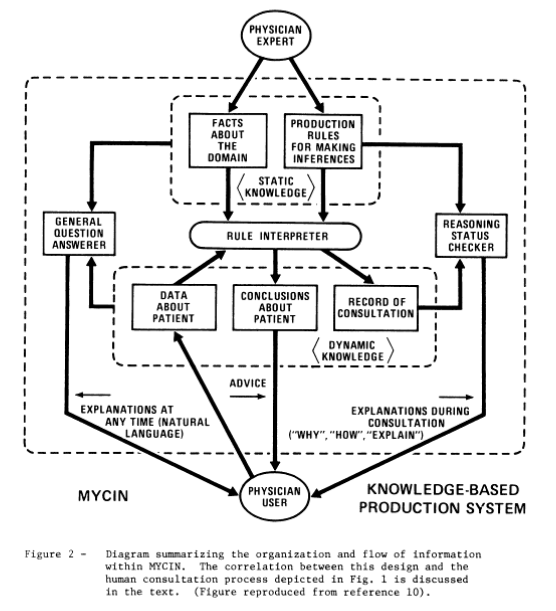
Due to the design requirements, MYCIN needed several interacting components each responsible for a subtask. At MYCINs core was the knowledge base, and a patient database, which both fed a group of subsystems: the consultation system, the explanation system, the question answering system, and the knowledge acquisition system.
– The consultation system gave advice to the clinician regarding the recommended therapy, based on inferences performed on the knowledge database and the patient database.
– The explanation system gave information regarding the reasoning behind recommended therapy and the knowledge base.
– The question answering system allowed the clinician to obtain information regarding the knowledge database, and the specific consultation.
– The knowledge acquisition system allowed the physician to extend MYCINs existing knowledge database with new information.